Sobre la función rx, o la forma lispiana de escribir expresiones regulares
No descubrimos ningún secreto, a estas alturas, si apelamos a la gran utilidad que tiene el manejo de expresiones regulares en la programación de Elisp. Ni tampoco al señalar lo antiestético y crudo que supone esa acumulación de signos arcanos que no resulta precisamente en el colmo de la transparencia. Una función en Elisp es fácil de leer e interpretar. Una sarta de expresiones regulares allí injertada requiere, por contra, echarle un poco de paciencia y ojímetro. Y muchas veces acabaremos encerrados en el monstruoso edificio que hemos construido con impecable lógica. Algo a lo que, a decir verdad, no quedaba más remedio que resignarse.
Y cuando uno ya estaba acostumbrándose a los encantos del masoquismo regexp, he aquí que va y descubre la existencia de
la función emacsiana rx, que nos permite escribir expresiones regulares como si fuesen expresiones de Elisp.
Naturalmente, y como bien apunta este blog (enlazo precisamente una entrada donde el lector encontrará un buen ramillete
de ejemplos de uso de rx), esta función no te exime de tu deber de conocer la sintaxis de las expresiones regulares.
De la misma forma que Magit no te va a librar de tener que conocer el uso de Git en la terminal. Pero son cosas que te
alegran un poco la vida. Al producir un código más inteligible y nítido que no desentona con la estética lispiana, la
ventaja evidente aquí con rx la encontramos a la hora de depurar nuestros trasteos y apaños.
Sobre el uso de la expresión rx y sus «sub-expresiones», invito a teclear C-h f o M-x describe-function <RET> rx
<RET> para acceder a la documentación. Pero veamos aquí un pequeño ejemplo con la expresión regular para localizar
numerales romanos que comentábamos en esta pasada entrada.
Nuestra expresión regular, escrita mediante la forma tradicional, sería ésta:
"\\(\\b[IVXLCDM]+\\b\\)"
¿Cómo lo traducimos a una expresión rx? Comencemos dende dentro.
- Cualquiera de los caracteres
IVXLCDM
(rx (any "IVXLCDM"))
Evaluado: [IVXLCDM]
- Que aparezca una o más veces
(rx (one-or-more (any "IVXLCDM")))
Evaluado: [IVXLCDM]+
- Y forme una palabra
(rx word-boundary (one-or-more (any "IVXLCDM")) word-boundary)
Evaluado: \\b[IVXLCDM]\\b
- Y todo ello se incluya en un grupo
(rx (group word-boundary (one-or-more (any "IVXLCDM")) word-boundary))
Evaluado, finalmente: "\\(\\b[IVXLCDM]+\\b\\)"
Ahora que nos venimos arriba, podemos ensayar una función que nos localice los numerales romanos después de la palabra
«siglo» (bien con un espacio mediante o un salto de línea), y nos lo encierre en un comando que ya teníamos definido en
LaTeX (\miscrom{ }) para convertir las mayúsculas en versalitas. La expresión (rx "siglo" (or space eol))
equivaldría a "siglo\\(?:[[:space:]]\\|$\\)" (es decir, la cadena «siglo» seguida de un espacio o de un corte de
línea). Por su parte, (rx "siglo \\miscrom{" (backref 1) "}") vendría a traducirse por "siglo \\\\miscrom{\\1}"
;; definimos una constante para nuestra expresión regular que localiza numerales romanos (defconst numeral-romano (rx (group word-boundary (one-or-more (any "IVXLCDM")) word-boundary))) (defun mis-romanos-a-versalitas () (interactive) (save-excursion (goto-char (point-min)) (replace-regexp (concat (rx "siglo" (or space eol)) (format "%s" numeral-romano)) (rx "siglo \\miscrom{" (backref 1) "}"))))
Ya sólo nos queda evaluarlo para ver si funciona:
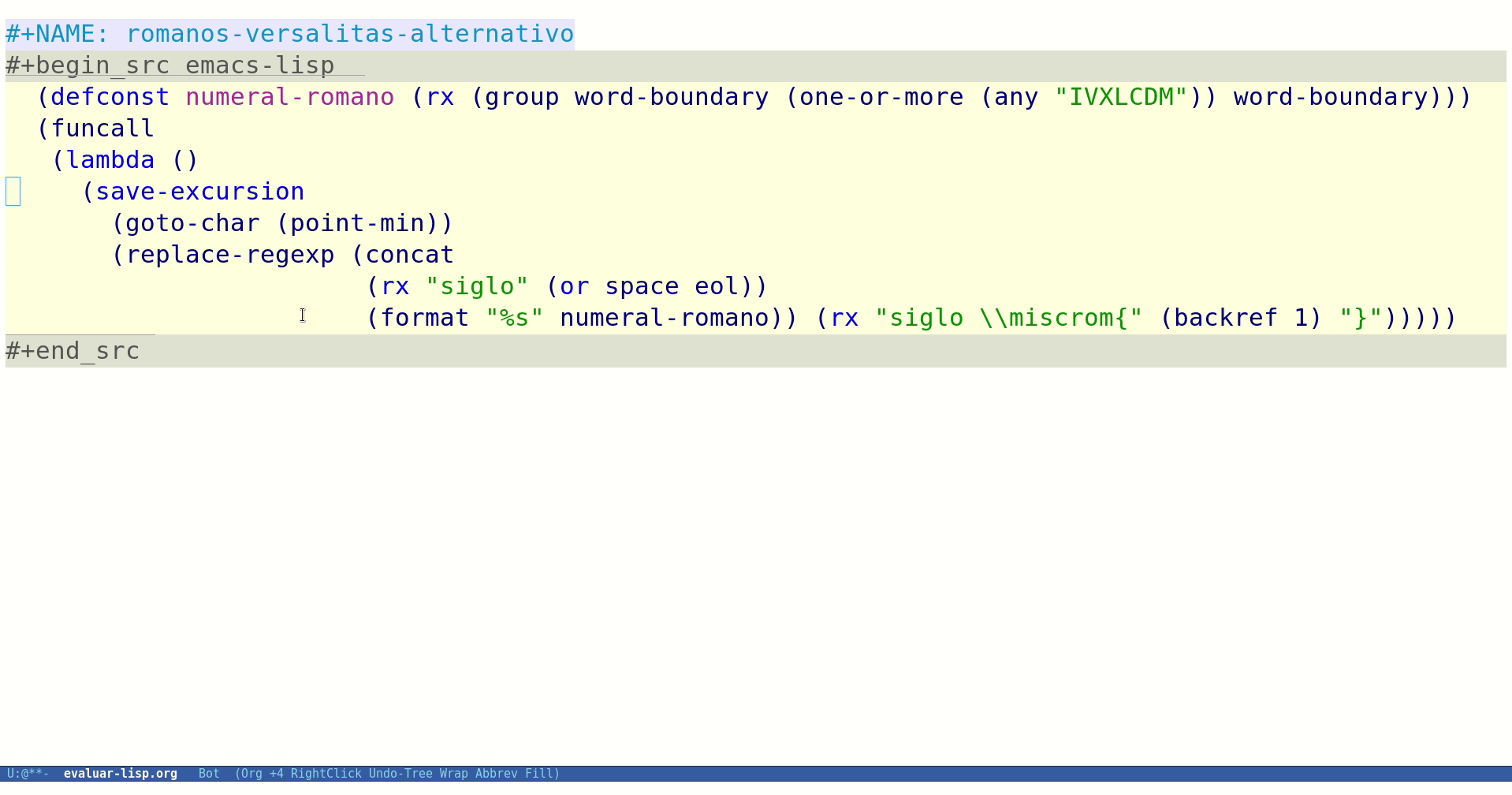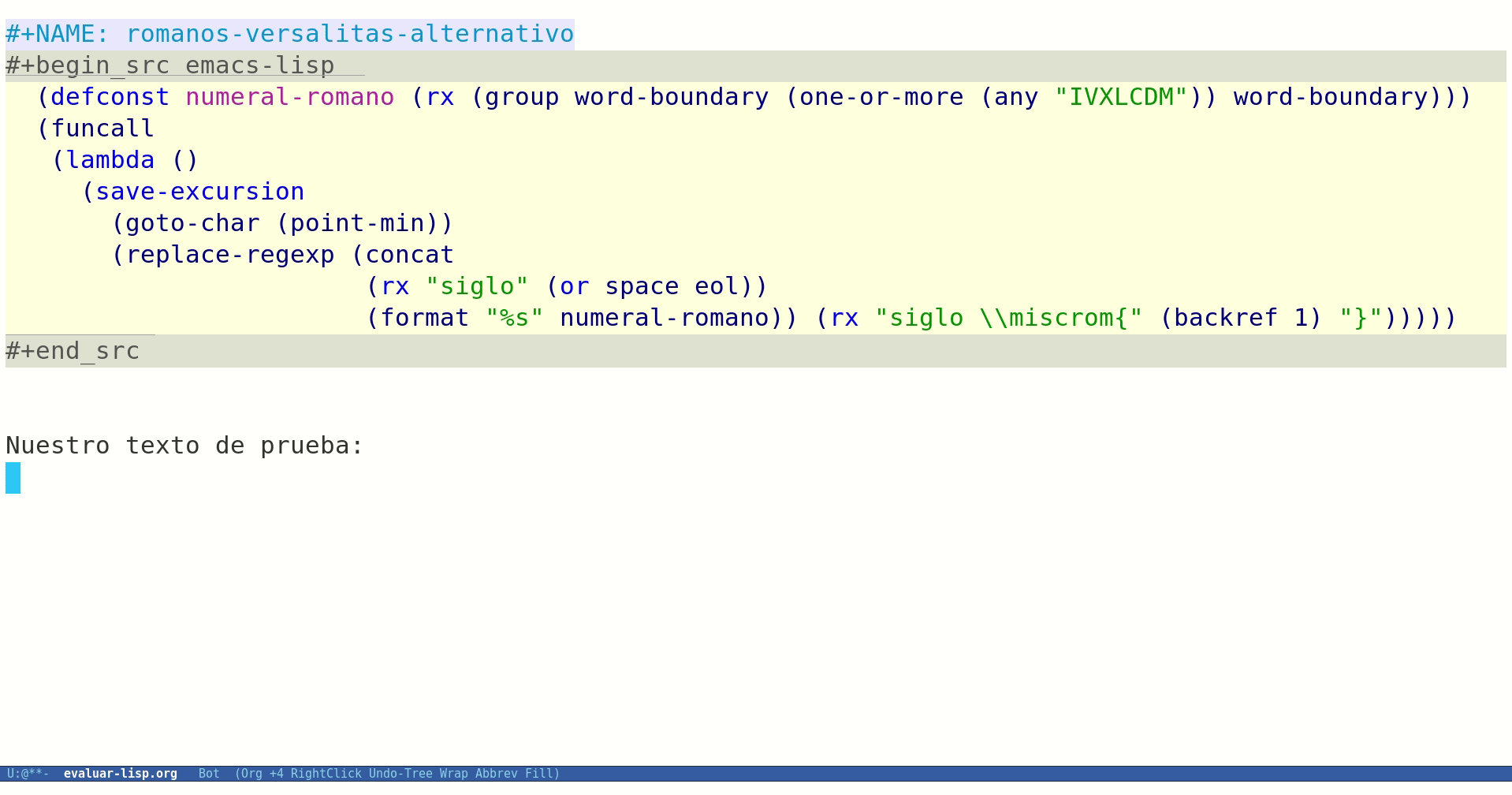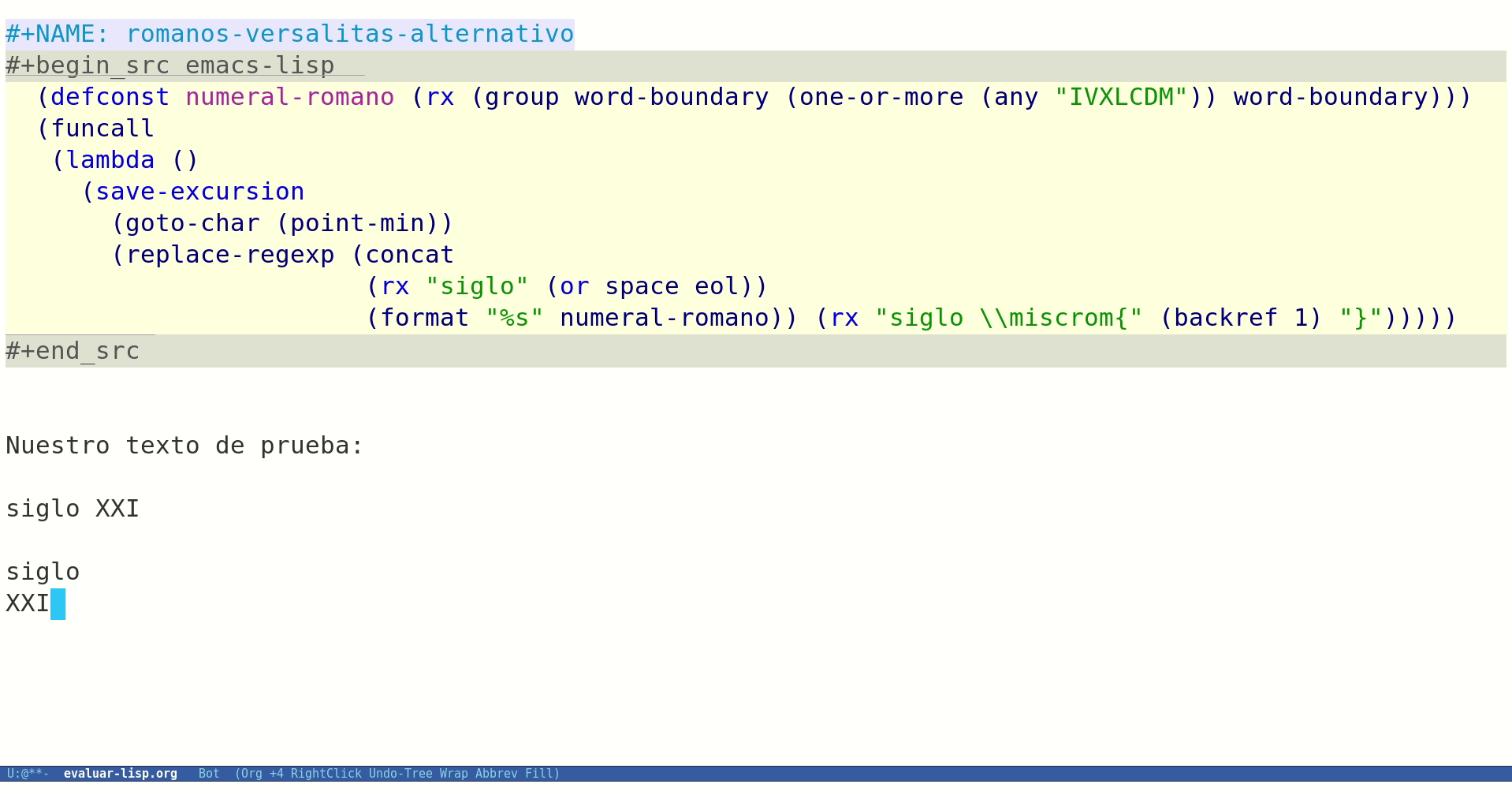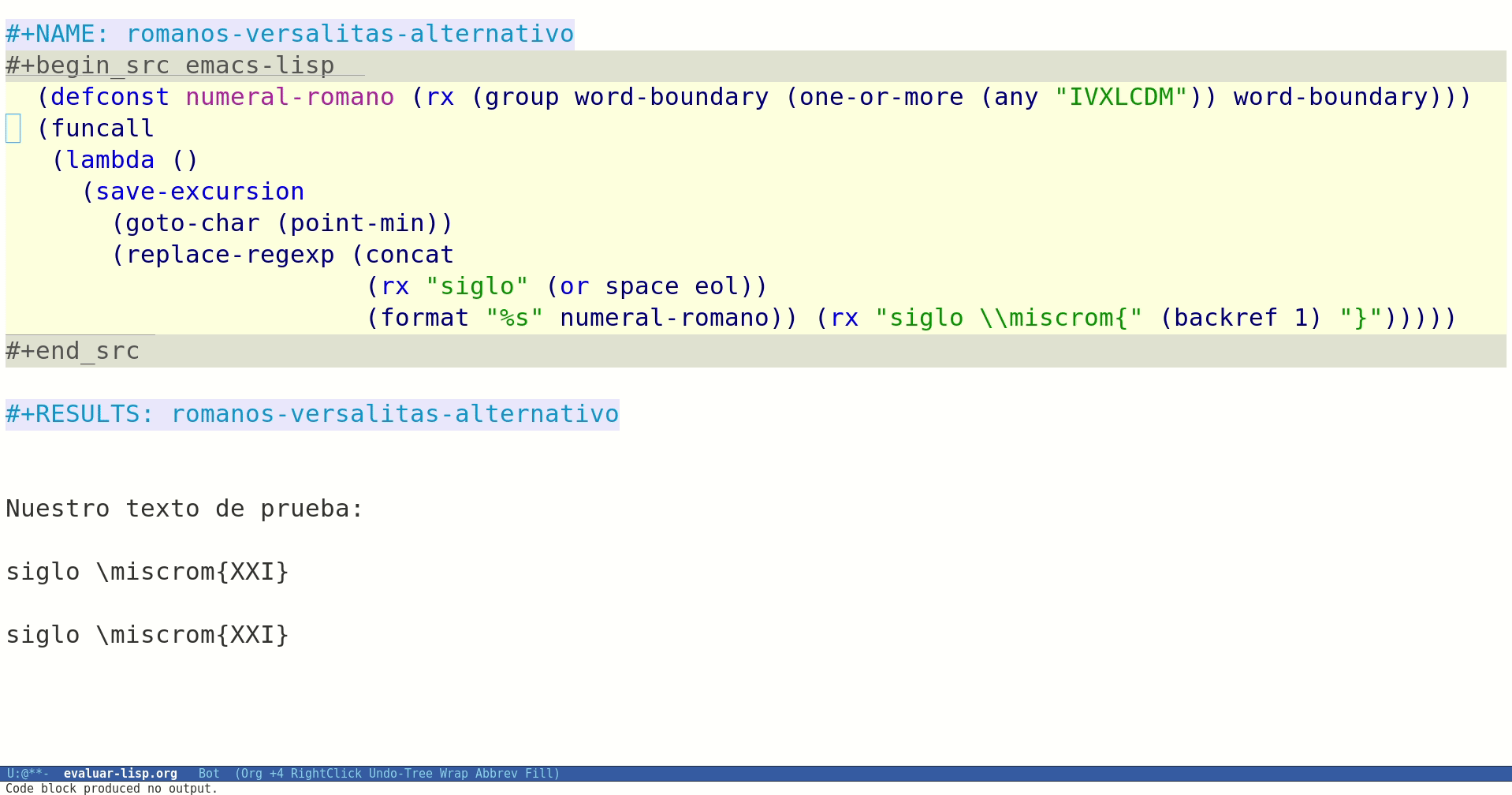
Figura 1: Evaluando nuestra función desde Org Mode
∞
Publicado: 23/08/2019
Última actualización: 23/08/2019
Esta obra está bajo una licencia de Creative Commons Reconocimiento-NoComercial 4.0 Internacional.